

PdfMasher--E-Book Conversion
If you've had problems reading PDF files on various devices (like mobile phones), PdfMasher may be just what you're looking for. According to the Web site:
PdfMasher is a tool to convert PDF files containing text in ready-for-e-book HTML files. Most e-book readers support PDF files natively, but it's often a real pain to read those documents, because we don't have font-size control over the document like we have with native e-books. In many cases, we have to use the zooming feature, and it's just a pain. Another drawback of PDFs on e-book readers is that annotations are not supported.
There are already tools to convert PDFs to e-books, like Calibre, but what they do is try to guess the role of each piece of text in the PDF (and that's if you're lucky). I think that in all but the simplest cases, it's a mistake to think that anything short of an AI can do that kind of guessing.
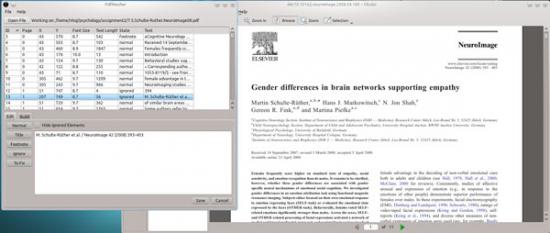
Using PdfMasher, PDF files like these can be manipulated manually for conversion into other formats.
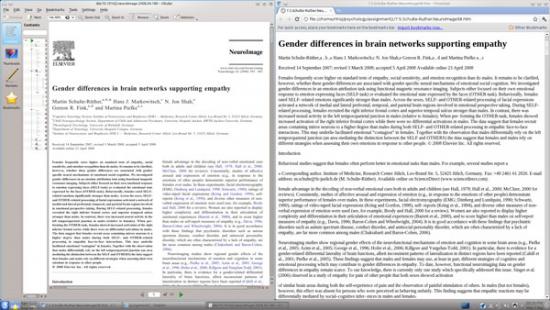
With the original PDF on the left and outputted HTML on the right, this e-book now can be read on any device without readability woes.
Installation
If you can install this with a binary, by all means do so. Available on the site are 32- and 64-bit Linux .deb packages for the ubiquitous Intel x86 architecture. For masochists, or those who don't have an Intel-based CPU, there is the obligatory source.
In order to grab the latest source, first you need to install hg, which was under the package name "mercurial" on my Kubuntu system. Once that's installed, grab the latest source by entering the command:
$ hg clone https://bitbucket.org/hsoft/pdfmasher
Once that has finished downloading, keep this terminal open where it is, because next you'll need to sort out the library requirements, and then you'll return to this terminal and continue the installation. As far as dependencies are concerned, the documentation lists the following:
-
Python 3.2 https://www.python.org
-
pdfminer3k https://hg.hardcoded.net/pdfminer3k
-
jobprogress 1.0.0 https://hg.hardcoded.net/jobprogress
-
Sphinx 1.0.7 https://sphinx.pocoo.org
-
pytest 2.0.3 to run unit tests https://pytest.org
-
Markdown 2.0.3 https://www.freewisdom.org/projects/python-markdown
-
PyQt 4.7.5 https://www.riverbankcomputing.co.uk/news
With the dependencies out of the way, re-open the terminal from before and enter the following commands:
$ cd pdfmasher
$ python configure.py
$ python build.py
Then, run the program with:
$ python run.py
If you're lucky enough to have the binary installed, you simply can run the program with the command:
$ pdfmasher
Usage
Before I try to explain how to use PdfMasher myself, I should include the following from the Web site:
PdfMasher asks the user about the role of each piece of text, and does it in an efficient manner. Your PDF has a header on each page, and you don't want them to litter your text? Sort text elements by Y-position (thus grouping them all together); Shift-select the elements and flag them as ignored. They will not appear on your final HTML. Your PDF has footnotes on many pages? Sort your elements by text content (thus grouping all elements with the text starting with a number together) and flag them as footnotes. They will be moved to the end of the document, and PdfMasher will try to create hyperlinks to footnote references.
Before changing things under PdfMasher, I recommend having your PDF open to one side in another program so you can cross-check bits of text as you're culling sections. When you're ready to start, click on Open File and choose the PDF you want to "mash".
Once open, the pane below fills up in a manner that at first glance is overwhelming and incomprehensible. However, on a very basic level, each line is a section of text in your PDF. If you explore each line, you can check which part of the PDF is being examined, and if it's redundant, you can choose to ignore it in the conversion.
Looking at these PdfMasher lines in detail, each line has an X and Y axis reference, as well as font size, text length and page number. Whenever you click a line, the full text content of its section in the PDF is shown in the pane below.
If you've decided on which sections to remove, click Ignore to cut out the text from the final product. Click Normal to reinstate the text for inclusion. Depending on which device you'll be reading the resulting e-book, the header and footer information may be something you want to cut out of the page.
For example, in the screenshot, I'm removing the beginning references and page headers in a psychology paper that otherwise would leave a hard-to-navigate, garbled mess if I translated it into something I could read on my phone.
However, if what you're preparing is intended to be something like a public Web page instead of a trimmed-down e-book, you might want to use the Title and Footnote buttons. Title will result in an H1 title header in the outputted HTML. The Footnote button will move the text to the bottom of the document, and PdfMasher will try to make one of the cool hyperlinks mentioned earlier.
Once you've finished editing your document, click on the Build tab below, and then click on the Generate Markdown button. A raw text file will be generated in the same folder as the original PDF. Click on Reveal Markdown, and the source folder will be opened in your default file manager. Edit Markdown will open the actual text file in your default text editor, and View HTML will show the end product in a Web browser.
If you've made any errors, the output will reveal them quickly, and you can go back and simply start the Build process again. From here, you either can leave your output as is or convert your files into specific e-book formats.
Either way, PdfMasher uses some very simple methods to create something very clever and is a must-have for any regular e-book reader.
Learn More: https://www.hardcoded.net/pdfmasher


Recent Articles






Corporate Patron

